高并發外賣系統的演進 數據處理與存儲支持服務
隨著移動互聯網的普及,外賣服務已成為現代生活的一部分,而高并發外賣系統在面對海量用戶請求時,其數據處理與存儲支持服務經歷了顯著的演進。本文將從系統演進的角度,探討數據處理與存儲支持服務在高并發外賣系統中的關鍵作用和發展路徑。
一、早期階段:關系型數據庫的局限性
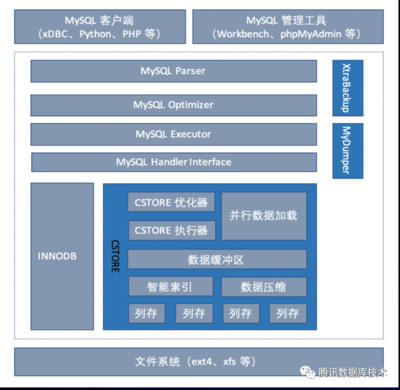
在高并發外賣系統的初期,業務量相對較小,系統主要依賴關系型數據庫(如MySQL)進行數據存儲。這種架構簡單易用,但面對用戶訂單的快速增長、實時庫存更新和配送狀態跟蹤等高并發場景時,關系型數據庫的瓶頸逐漸顯現。例如,數據庫連接數限制、讀寫性能下降,導致系統響應延遲,影響用戶體驗。此時,系統主要采用垂直擴展(如提升硬件性能)來緩解壓力,但成本高昂且擴展性有限。
二、演進中期:引入分布式緩存與讀寫分離
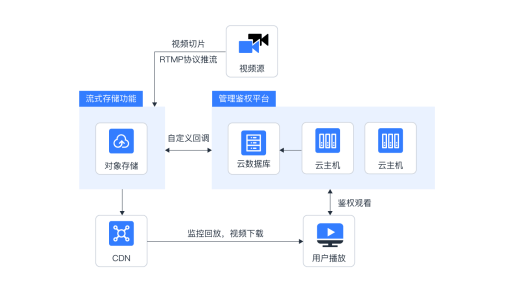
為應對高并發挑戰,系統開始引入分布式緩存(如Redis)來緩存熱點數據(如菜單信息、用戶會話),減少數據庫的直接訪問壓力。同時,通過讀寫分離技術,將讀操作分流到從庫,寫操作集中在主庫,提升了系統的吞吐能力。這一階段還采用了消息隊列(如Kafka或RabbitMQ)來處理異步任務,例如訂單創建后的通知和日志記錄,確保系統的可靠性和可擴展性。數據處理方面,系統開始使用批處理工具(如Hadoop)對歷史訂單數據進行分析,以優化庫存和配送策略,但實時性仍有限。
三、現代階段:微服務與NoSQL數據庫的整合
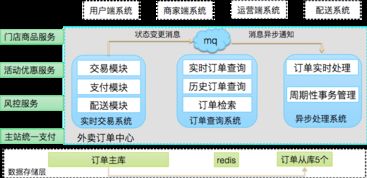
隨著業務復雜度的增加,外賣系統演進為微服務架構,將訂單、支付、配送等模塊解耦,每個服務獨立部署和擴展。在數據處理與存儲方面,系統廣泛采用NoSQL數據庫(如MongoDB用于存儲非結構化數據,Elasticsearch用于快速搜索訂單),并結合時序數據庫(如InfluxDB)處理實時監控數據。數據存儲支持服務通過分布式文件系統(如HDFS)和對象存儲(如AWS S3)來管理大規模數據,確保高可用和持久性。實時數據處理框架(如Apache Flink或Spark Streaming)被用于實時分析用戶行為和訂單趨勢,提升了系統的智能化水平,例如動態定價和智能推薦。
四、未來展望:AI與云原生技術的融合
未來,高并發外賣系統將向更智能、更彈性的方向發展。數據處理將深度融合AI技術,通過機器學習模型預測需求峰值和優化資源分配;存儲支持服務將基于云原生架構(如Kubernetes和Serverless),實現自動擴縮容和成本優化。同時,邊緣計算的引入將進一步提升數據處理速度,減少延遲。總體而言,數據處理與存儲支持服務的演進將持續推動外賣系統在高并發場景下的穩定性和效率。
高并發外賣系統的演進不僅依賴于技術創新,還在于數據處理與存儲支持服務的不斷優化。從傳統數據庫到分布式架構,再到智能云原生,每一步都體現了對高并發挑戰的應對策略。未來,隨著技術的進步,這一領域將迎來更多突破,為用戶提供更流暢、可靠的服務體驗。
如若轉載,請注明出處:http://www.elnur.cn/product/13.html
更新時間:2026-01-08 03:30:49